What's New
Changelog - 5.0.1
Release 5.0
Changelog - 4.3.4
Changelog - 4.3.3
Changelog - 4.3.2
Changelog - 4.3.1
Release 4.3 (Fall 2023)
Changelog - 4.2.7
Changelog - 4.2.6
Changelog - 4.2.5
Changelog - 4.2.4
Changelog - 4.2.3
Changelog - 4.2.2
Changelog - 4.2.1
Release 4.2
Changelog - 4.1.5
Changelog - 4.1.4
Changelog - 4.1.3
Changelog - 4.1.2
Changelog - 4.1.1
Release 4.1
Release 4.0
Release 3.9
Release 3.8
Release 3.7
Release 3.6
Release 3.5
Release 3.4
Release 3.3
Release 3.2
Release 3.1
Release 3.0
Release 2.4.1
Release 2.4
Free Cloud Trial
Release 1.8
Release 2.3
Release 2.2
Release 2.1
Release 2.0
Release 1.7
Release 1.6
Release 1.5
Getting Started
Quick Guide
Best Practices Guide
Search - Best Practices
Vizpads (Explore) - Best Practices
Insights (Discover) - Best Practices
Predict - Best Practices
Data - Best Practices
Glossary
Tellius 101
Navigating around Tellius
System requirements
Tellius Architecture
Installation steps for Tellius
Guided tours for quick onboarding
Customizing Tellius
Tellius Copilot 101
Search (Natural Language)
Search in Tellius
Guide Me
How to Search
Business View List / Columns
Query
Query
Percentage Queries
Time Period Queries
Live Query
Generating Insights-based queries from Search
Search Result
Discover Insights
Interactions
Chart Operations
Add to Vizpad
Table View
Switch Chart type
Change Chart Config
Apply Filters
Change Formatting
Measure Aggregation - Market Share Change
View Raw Data
Download/ Export
Embed URL
Partial Data for Visualization
Best-fit visual
Add to Vizpad
Adding the chart to a Vizpad
Customize the auto-picked columns
Search Query Inspector
Teach Tellius
GPT mode in Search
History
Guided Search
Add Guided Search Experience
Display Names in the Search Guide
Guided Search
Guided Search Syntax and Attributes
Deep Dive
Maps in Search
Search Keywords
Percentage Queries
Time Period Queries
Year-over-Year Analysis
Additional Filters
Pagination
List View In Search Results
Marketshare queries
Embed Search
Personalized Search
Search Cheat Sheet
Filters in Help Tellius Learn
Explore (Vizpads)
Dashboards in Tellius
Vizpad Creation
Create Interactive Content
Create Visualization Charts
List of Charts
Common Chart Types
Line Chart
Bar Chart
Pie Chart
Year-over-Year Functionality in Vizpad
Area Chart
Combo Chart
KPI Target Chart
Treemaps
Bubble Chart
Histogram
Heat-Map Charts
Scatter Chart
Other Charts
Cumulative line chart
Cohort Chart
Explainable AI Charts
For each chart
Create Visualization Charts
Global Filters
Embedded Filters
Other Content
Anomaly management for charts
Creating Interactive Content
Vizpad level Interactions
Viz level Interactions
Discover Insights
Drivers
Discover hidden insights - Genius Insights
How Genius Insights works
Discoveries in Insight
Anomalies on Trend
Interactions
Chart Operations
Switch Chart type
Change Chart Config
Apply Filters
Change Formatting
Add X/Y Axis Target Lines to Scatter Chart
Improvements to Conditional Formatting
Adding Annotations to Tables
Displaying query execution time
AI summaries
Embedding Vizpad
Vizpad Consumption
Collection of Interactive Content
Vizpad level Interactions
Global Filter on the fly
Global Resolutions
Refresh
Notifications / Alerts
Share
Download / Export
Unique name for Vizpads
Edit Column Width
Viz level Interactions
Importing bulk filter values
Multi-Business View Vizpads
Discover (Genius Insights)
Discoveries
What are discoveries
Type of Discoveries in Tellius
Create Discoveries
Kick-off Key Drivers
Edit Insights
Key Driver Insights
Components of Key Drivers
What are Key Drivers
Edit Key Driver Insights
Segment Drivers
Trend Drivers
Trend Insights (Why Insights)
Components of Trend Insights
WHAT: Top Contributors
WHY: Top Reasons
HOW: Top Recommendations
Seamlessly navigating to "Why" from "What"
Create Trend Insight
Edit Trend Insights
What are Trend Insights
Comparison Insights
Components of Comparison Insights
Create Comparison Insight
What are Comparison Insights
Edit Comparison Insights
Others Actions
Save
Refresh
Share Insights
Download
Adding Insights to Vizpad
Insights Enhancements
Embedding Insight
Impact Calculation for Top Contributors
Marketshare
Live Insights
Predict (Machine Learning)
Machine Learning
AutoML
How to create AutoML models
Leaderboard
Prediction
Others
What is AutoML
Point-n-Click Predict
Feed (Track Metrics)
Assistant (Conversations)
Tellius on Mobile devices
Data (Connect, Transform, Model)
Connectors
Connector Setup
Google BigQuery
Google Cloud SQL
Connecting to a PostgreSQL Cloud SQL Instance
Connecting to an MSSQL Cloud SQL Instance
Connecting to a MySQL Cloud SQL Instance
Snowflake
PrivateLink
Snowflake Best Practices
OAuth support for Snowflake
Integrating Snowflake with Azure AD via OAuth
Integrating Snowflake with Okta via OAuth
Edit Connector
Live Connect
Data Import
Cache
Direct Business View
JDBC connector for PrestoDB
Amazon S3
Looker SQL Interface
Databricks
Connecting to an AlloyDB Cluster
List of Connectors by Type
Tables Connections
Custom SQL
Schedule Connector Refresh
Share Connections
Datasets
Load Datasets
Configure Datasets (Measure/Dimensions)
Transform Datasets
Create Business View
Share Datasets
Copy Datasets
Delete Datasets
Swapping datasources
Metadata migration
Data Prep
Datasets
Data Profiling / Statistics
Transformations
Dataset Transform
Aggregate Transforms
Calculated Columns
SQL Transform
Python Transform
Create Hierarchies
Filter Data
SQL Code Snippets
Multiple Datasets Scripting SQL
Column Transforms
Column Metadata
Column type
Feature type
Aggregation
Data type
Special Types
Synonym
Rename Column
Filter Column
Delete Column
Variable Display Names
Other Functions
Metadata View
Dataset Information
Dataset Preview
Alter Pipeline Stage
Edit / Publish Datasets
Data Pipeline (Visual)
Alerts
Partitioning for JDBC Datasets
Export Dataset
Write-back capabilities
Data Fusion
Schedule Refresh
Business Views
Create Business View
Create Business View
Datasets Preview & List
Add datasets to Model
Joins
Column selection
Column configuration
Primary Date
Geo-tagging state/country/city
Save to Fast Query Engine
Publish
Business View
What is Data Model
BV Visual Representation (Preview)
BV Data Sample
Learnings (from Teach Me)
Custom Calculations (Report-level Calc)
Predictions on BV
BV Refresh
Export/ Download Business View
Share Business View
URL in Business View
Request Edit Access
Projects (Organize Content)
Monitor Tellius
Embedding Tellius
Embedding
Settings
About Tellius
User Profile
Admin Settings
Manage Users
Team (Users)
Details & Role
Create a new user
Edit user details
Assigning the user data to another user
Restricting the dataset for a user
Deleting a user
Assign User Objects
Teammates (Groups)
Authentication & Authorization
Application & Advanced Settings
Data
Machine Learning
Genius Insights
Usage tracking & Support
CDN
Download Business View, Dataset, and Insights for Live BV
Customize Help
Impersonate
Data Size Estimation and Calculation
Miscellaneous Application Settings
Configuration for time/date-related results
Dataflow Access
Enable In-memory operations on Live sources
Language Support
Administration
Setup & Configuration
Installation Guide
AWS Marketplace
Autoscaling
Backup and Restore
Help & Support
FAQ
Data Preparation FAQs
Environment FAQs
Search FAQs
Vizpads FAQs
Data Caching
Security FAQs
Embedding FAQs
Insights FAQs
Tellius Product Roadmap
Help and Support System
Guided Tours
Product Videos
Articles & Docs
Provide Feedback
Connect with Tellius team
Support Process
Notifications
Getting Started Videos
Getting Started
Tellius Connect
Tellius Data Overview Video
Connecting to Flat Files Video
Connecting to Data Sources Video
Live Connections Video
Data Refresh and Scheduling Video
Tellius Prep
Getting Started with Tellius Prep Video
Transformations, Indicators, Signatures, Aggregations and Filters Video
SQL and Python Video
Working with Dates Video
Data Fusion Video
Business View Video
Business Mapping Video
Report Level Calculations Video
Writeback to DB
Natural Language Search
Getting Started with Search Video
How-To Search Video
Customizing Search Results Video
Search Interactions Video
Help Tellius Learn
Explore - Vizpads
Getting Started with Vizpads Video
Creating Vizpads Video
Creating and Configuring Visualizations Video
Viz-Level Interactions Video
Vizpad-Level Interactions Video
Auto Insights
Getting Started with Auto Insights Video
Discovery Insights Video
Segment Insights Video
Trend Insights Video
Comparison Insights Video
Iterate on Insights Video
Tellius Feed Video
Predict - ML Modeling
Getting Started with Predict Video
AutoML Configuration Video
AutoML Leaderboard Video
Point-n-Click Regression Video
Point-n-Click Classification Video
Point-n-Click Clustering Video
Point-n-Click Time Series Video
Point-n-Click PythonML Video
PredictAPI Video
Apply ML Model Video
ML Refresh and Schedule Video
Admin
Best Practices & FAQs
API Documentation
Vizpad APIs
User & user groups APIs
Machine Learning APIs
Fall 2023 (4.3)
- All Categories
- Data (Connect, Transform, Model)
- Data Prep
- Datasets
- Partitioning for JDBC Datasets
Partitioning for JDBC Datasets
Data Partitioning
In order to improve the performance of the data load, Tellius introduces partitioning of the data. This will make the data load faster into the system, especially when the data sizes increase. User needs to provide the Partition Column and Number of Partitions followed by Lower and Upper bounds. Upper bound and Lower bounds are the Minimum and Maximum value of the column.
There need not be single unique key in the dataset. Partition key can be any numeric key which has uniform distribution. For instance if the data has data for 10 years (2010 - 2020) and there is a year column. It can be used for partitioning.
Min - 2010
Max - 2020
Number of partitions - 12
This will actually load the data into 12 different partitions with the following logic.
- Partition 1 < 2010
- Partition 2 : 2010 - 2011
- Partition 3 : 2011 - 2012
- Partition 4 : 2012 - 2013
- Partition 5 : 2013 - 2014
- Partition 6 : 2014 - 2015
- Partition 7 : 2015 - 2016
- Partition 8 : 2016 - 2017
- Partition 9 : 2017 - 2018
- Partition 10 : 2018 - 2019
- Partition 11 : 2019 - 2020
- Partition 12 : >2020
Thumb rule for the number of partitions is to have 1 to 2 million rows per partitions. If the data has 16M rows, then it can have 8 or 10 partitions.
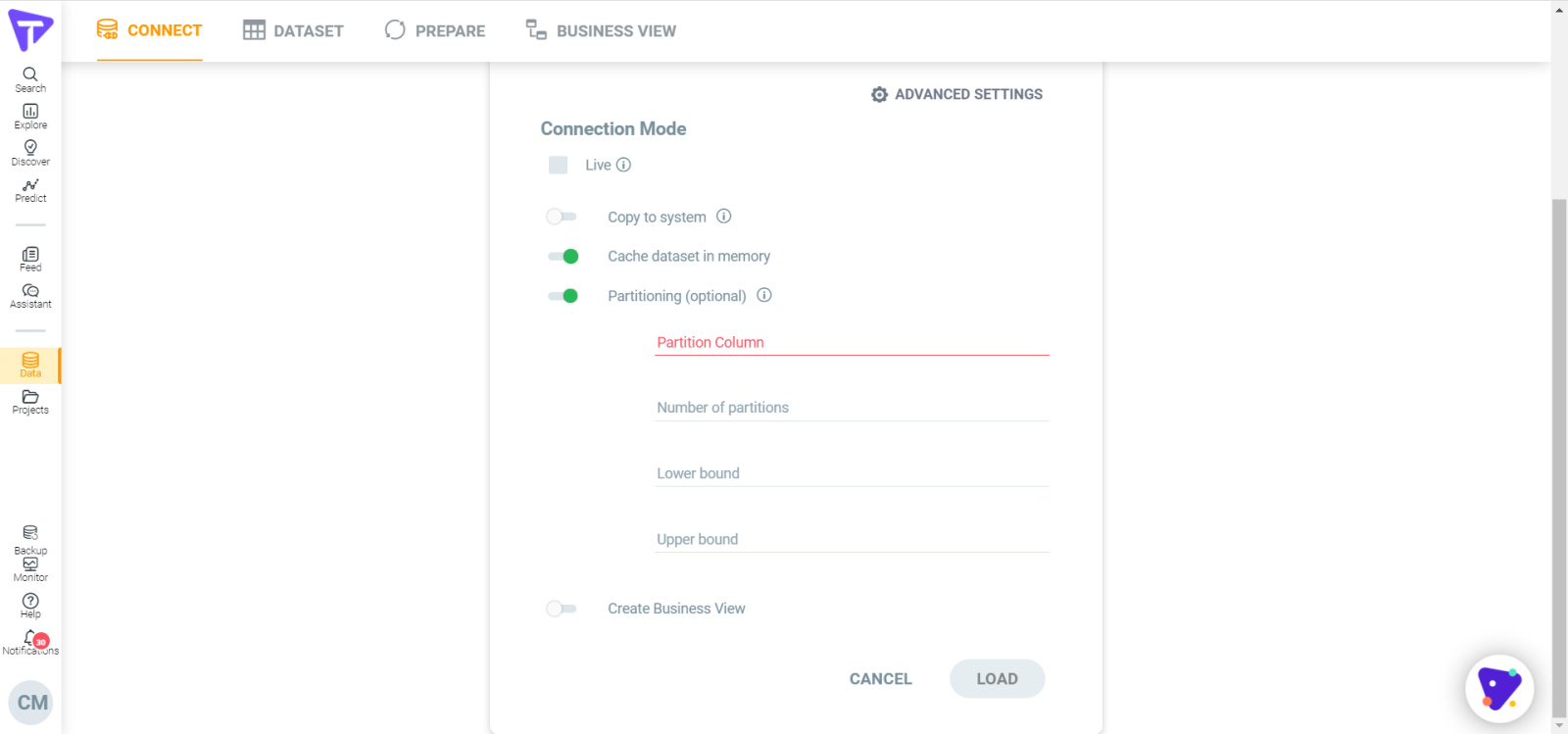
How to set partitions for JDBC data load?
1. Login to Tellius and open the Data from the side menu bar.
2. Go to CONNECT and click on CREATE NEW button, it will open the available data connectors for data load.
3. From the list of connectors, select the JDBC connector.
4. Load the data and click on ADVANCE SETTINGS to load additional options.
5. Set partitions values Like Partition column, Number of Partitions, Lower bound, Upper bound in Data Partitioning for JDBC Data load and click on LOAD.
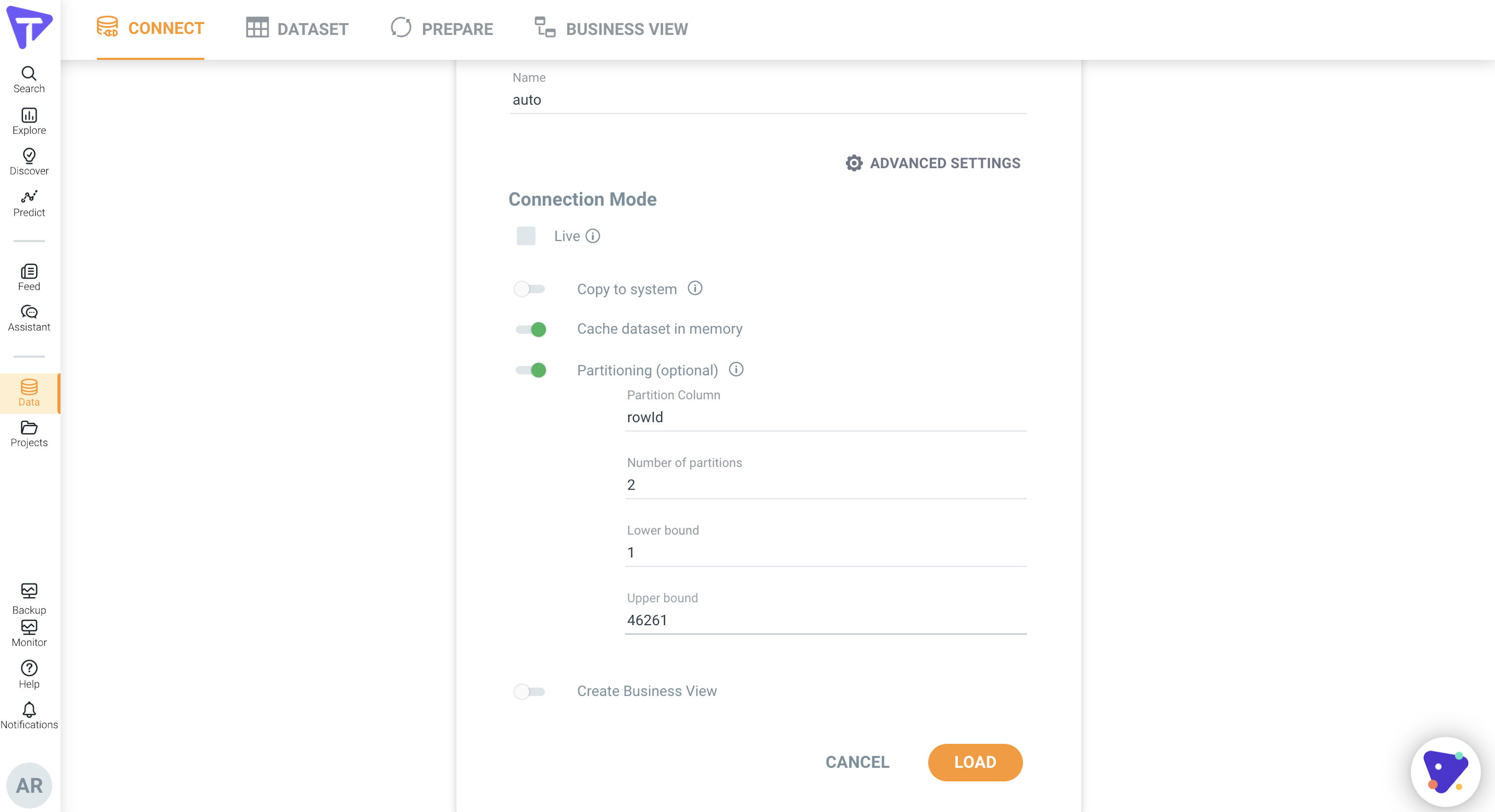
Data Partitioning - SQL Data, JDBC Data
This functionality helps to improve the performance of data loading by partitioning the data. It helps to load the data faster into the system, especially when the data size increases. You need to provide the Partition Column and Number of Partitions followed by Lower and Upper bounds. Upper bound and Lower bounds are the Minimum and Maximum values of the column.
There need not be a single unique key in the dataset. A partition key can be any numeric key that has a uniform distribution. For instance, if the data has data for 10 years (2010 - 2020) and there is a year column. It can be used for partitioning.
Min – 2010
Max - 2020
Number of partitions - 12
This will load the data into 12 different partitions with the following logic.
1. Partition 1 < 2010
2. Partition 2: 2010 – 2011 and so on.
The Thumb rule for the number of partitions is to have 1 to 2 million rows per partition. If the data has 16M rows, then it can have 8 or 10 partitions.
To set the Partitions:
1. Click Data and click CONNECT.
2. Click CREATE NEW button, it will open the available data connectors for data load.
3. From the list of connectors, select the MYSQL connector.
4. Load the data and click ADVANCE SETTINGS to load additional options.
5. Set partitions values Like Partition column, Number of Partitions, Lower bound, Upper bound in Data Partitioning for MYSQL Data load and click LOAD.